易课寄在线购课系统开发笔记(二十)–把搜索功能切换到SolrCloud
什么是 SolrCloud
SolrCloud (Solr 云) 是 Solr 提供的分布式搜索方案,当你需要大规模、容错、分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用 SolrCloud 的,当索引量很大,搜索请求并发很高,这时需要使用 SolrCloud 来满足这些需求。 SolrCloud 是基于 Solr 和 ZooKeeper 的分布式搜索方案,它的主要思想是使用 ZooKeeper 作为集群的配置信息中心。 它有几个特色功能: 1)集中式的配置信息 2)自动容错 3)近实时搜索 4)查询时自动负载均衡
Solr 集群的系统架构
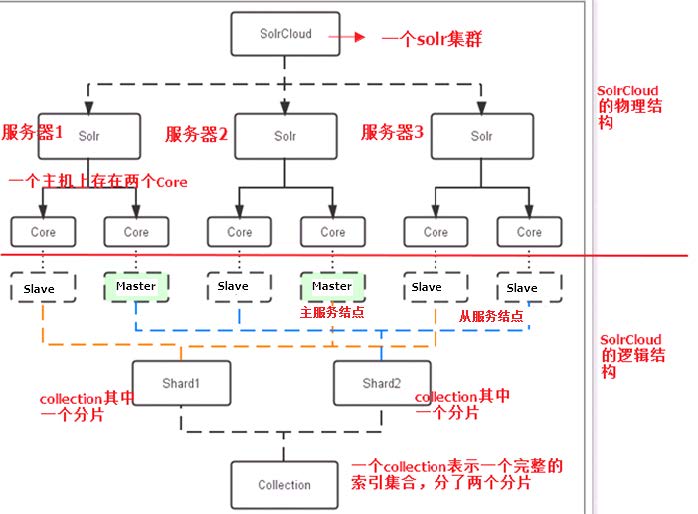
物理结构
三个 Solr 实例( 每个实例包括两个 Core),组成一个 SolrCloud。
逻辑结构
索引集合包括两个 Shard(Shard1 和 Shard2),Shard1 和 Shard2 分别由三个 Core 组成,其中一个 Leader 两个 Replication,Leader 是由 ZooKeeper 选举产生,ZooKeeper 控制每个 Shard 上三个 Core 的索引数据一致,解决高可用问题。
用户发起索引请求分别从 Shard1 和 Shard2 上获取,解决高并发问题。
Collection
Collection 在 SolrCloud 集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个 Shard(分片),它们使用相同的配置信息。
比如:针对课程信息搜索可以创建一个 Collection。
Collection = Shard1 + Shard2 + …. + ShardX
Core
每个 Core 是 Solr 中一个独立运行单位,提供索引和搜索服务。一个 Shard 需要由一个 Core 或多个 Core 组成。由于 Collection 由多个 Shard 组成,所以 Collection 一般由多个 Core 组成。
Master 或 Slave
Master 是 Master-Slave 结构中的主结点(通常说主服务器),Slave 是 Master-Slave 结构中的从结点(通常说从服务器或备服务器)。同一个 Shard 下 Master 和 Slave 存储的数据是一致的,这是为了达到高可用目的。
Shard
Collection 的逻辑分片。每个 Shard 被化成一个或者多个 Replication,通过选举确定哪个是 Leader。
需要实现的 Solr 集群架构
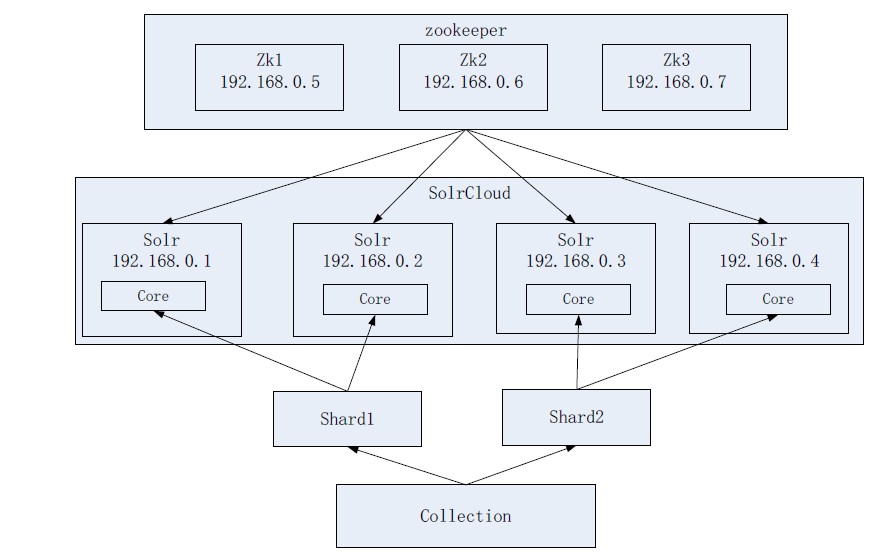
ZooKeeper 作为集群的管理工具。
1、集群管理:容错、负载均衡。
2、配置文件的集中管理
3、集群的入口
需要实现 ZooKeeper 高可用,需要搭建集群,建议是奇数节点。至少需要三个 ZooKeeper 服务器。
搭建 Solr 集群需要 7 台服务器。
安装及搭建步骤
请参考下面这篇笔记:
CentOS 6学习笔记(十四)–CentOS6环境搭建Solr集群(SolrCloud)
使用 SolrJ 管理集群
添加文档
使用步骤:
第一步:把 SolrJ 相关的jar 包添加到工程中;
第二步:创建一个 SolrServer 对象,需要使用 CloudSolrServer 子类。构造方法的参数是 ZooKeeper 的地址列表;
第三步:需要设置 DefaultCollection 属性;
第四步:创建一个 SolrInputDocument 对象;
第五步:向文档对象中添加域;
第六步:把文档对象写入索引库;
第七步:提交。
@Test
public void testSolrCloudAddDocument() throws Exception {
// 第一步:把solrJ相关的jar包添加到工程中。
// 第二步:创建一个SolrServer对象,需要使用CloudSolrServer子类。构造方法的参数是zookeeper的地址列表。
//参数是zookeeper的地址列表,使用逗号分隔
CloudSolrServer solrServer = new CloudSolrServer("192.168.25.155:2181,192.168.25.155:2182,192.168.25.155:2183");
// 第三步:需要设置DefaultCollection属性。
solrServer.setDefaultCollection("collection2");
// 第四步:创建一SolrInputDocument对象。
SolrInputDocument document = new SolrInputDocument();
// 第五步:向文档对象中添加域
document.addField("item_title", "测试课程");
document.addField("item_price", "100");
document.addField("id", "test001");
// 第六步:把文档对象写入索引库。
solrServer.add(document);
// 第七步:提交。
solrServer.commit();
}
查询文档
创建一个 CloudSolrServer 对象,其他处理和单机版一致。
把搜索功能切换到集群版
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context" xmlns:p="http://www.springframework.org/schema/p"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.2.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.2.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.2.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.2.xsd
http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-4.2.xsd">
<!-- 集群版solrJ -->
<bean id="cloudSolrServer" class="org.apache.solr.client.solrj.impl.CloudSolrServer">
<constructor-arg index="0" value="solr:2181,solr:2182,solr:2183"></constructor-arg>
<property name="defaultCollection" value="collection2"></property>
</bean>
</beans>